안녕하세요. 어쩌다가 시작한 컴퓨터 잡학지식의 Eiden입니다.
연구실에서 Pose Detection 관련 클리닉을 진행하며, Yolov8n보다 성능 좋은 Mediapipe의 Pose Detection Task 코드를 보던 중 다중 포즈 감지 모델에 대한 옵션을 알게 되었습니다.
아마 구글에서 검색했을때 Multi Person Pose Detectino에 대한 Mediapipe의 Document에 기재되어 있지 않아, 다중 사람에 대한 포즈를 추적해야 하는 사람들에게 도움이 됐으면 하는 바람에 코드 공유 및 개념에 대해 설명드리려 합니다.
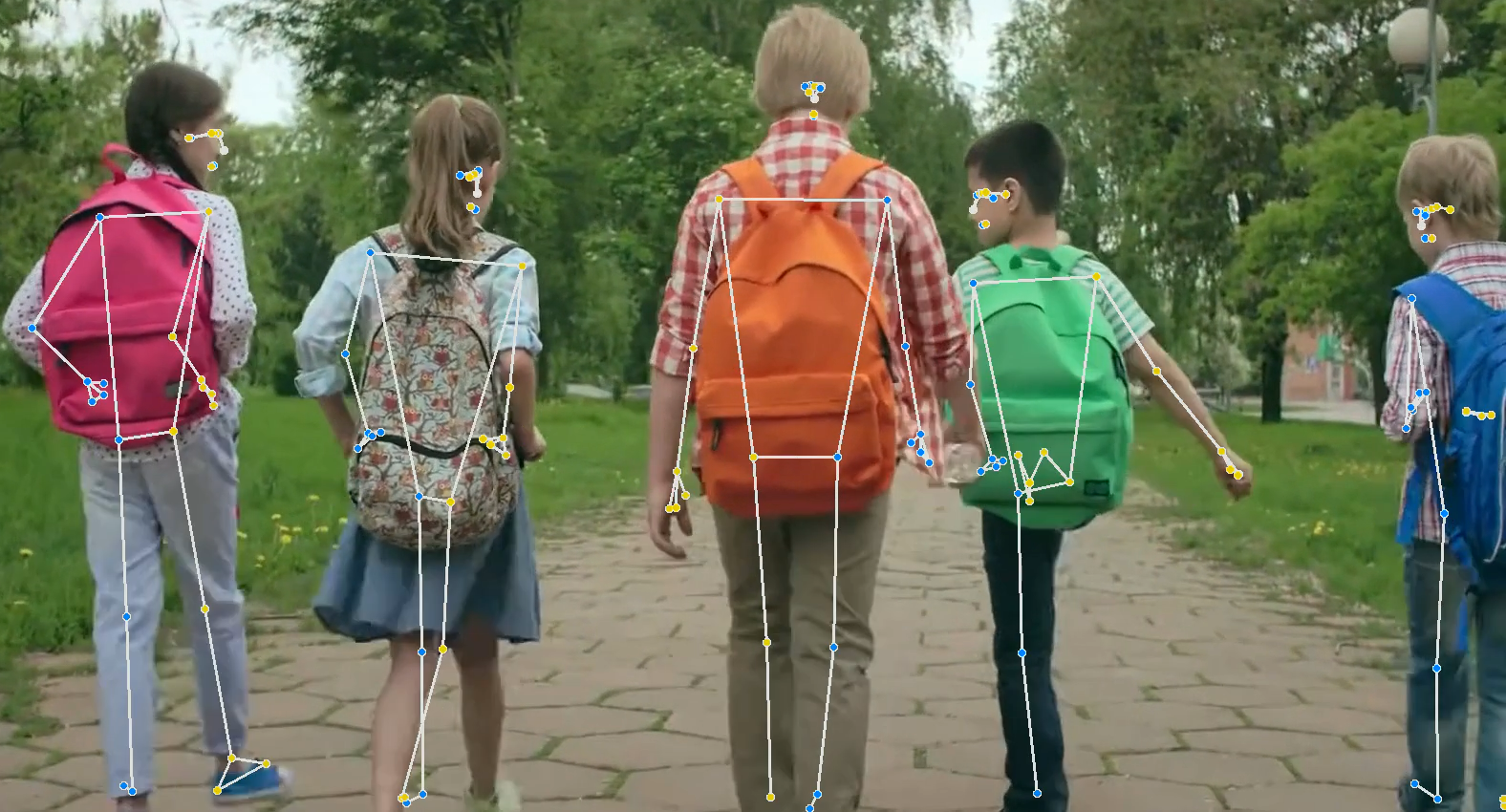
- Mediapipe Pose Detection model : BlazePose Model
미디어파이프에서 제공하는 BlazePose Model은 Mediapipe의 Documentation에 적혀있다시피 Single Person에 대한 최적화가 진행되어 있습니다. 이 모델은 33개의 키포인트를 추적할 수 있고, 실시간으로 복잡한 Pose에 대해 추적할 수 있습니다.
BlazePose의 핵심은 위의 그림과 같이 두 단계로 구성된 Detector-Tracker ML Pipeline으로 구성되어 있는데요.
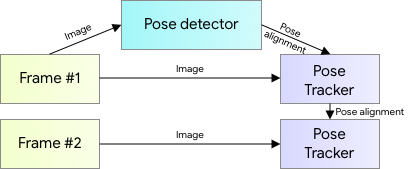
첫 번째 단계인 Detector는 프레임 내에서 포즈에 대한 관심 영역(ROI)를 찾아냅니다. 쉽게 말해서 사람을 인식하고 사람에 대한 관절 및 형태에 대한 추론을 하지 않고, 프래임(이미지) 내에서 Pose를 추정하기 위해 필요한 관절 관심 영역(ROI)을 바로 찾아낸다고 할 수 있습니다. 따라서 사람인 부분을 잠재적으로 추론하여, 관절을 Detect 한다고 할 수 있습니다.
두 번째 단계인 Tracker는 이 관심영역(ROI)에서 모든 33개의 Pose Keypoint를 예측합니다. 비디오 입력 방식에서는 Detector가 첫 번쨰 프레임에서만 실행되고, 이후 프레임에서는 이전 프레임의 Pose Keypoint를 바탕으로 ROI를 추론하는 형식으로 구성되어 있습니다.
따라서 우리가 사람 객체를 인식하고 이에 대한 정확한 ROI를 Detect하는 방식과 다르게 MediaPipe Pose는 각 프레임 내 포즈를 감지하는 특정한 내부 메커니즘이 있다는 것을 알 수 있죠. 그렇기에 혹여나 사람 감지가 필요하다면 STATIC_IMAGE_MODE와 같은 설정을 통해 각 입력이미지에 대해 사람 감지도 수행할 수 있습니다. (비디오나 Real-time Source에는 처리 속도가 늘어나기에 사용하지 않는 것이 더 좋을 수 있습니다.)
다중 인물 탐지를 위한 명시적인 방법은 Mediapipe Documentation(https://developers.google.com/mediapipe/solutions/vision/pose_landmarker#get_started)에 적혀있지 않은 것으로 확인되나 첫 번째 프레임 내 모든 관절을 Detect하는 Detector에 옵션값(num_pose)으로 몇개의 관절 묶음(사람의 형태를 띄겟죠)들을 지정하고 두 번째 프레임부터 첫 번쨰 프레임에 대한 ROI 를 활용해 추적하도록 하면 Multi Person Pose Detect를 할 수 있을 것이라 생각합니다.
아래와 같이 mediaipipe.tasks.python.vision 함수를 활용해 초기 설정시 옵션으로 사람감지 및 다중 인물 자세 추정을 수행할 수 있으니 참고해 주시면 좋을 것 같습니다.
- Code
import cv2
import numpy as np
import mediapipe as mp
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
from mediapipe.framework.formats import landmark_pb2
from tkinter.messagebox import showinfo
import time
import tempfile
import os
class PoseMultiDetector:
def __init__(self, video_path:list, load_dir:str, save_dir:str, model_path:str, num_poses=5, min_pose_detection_confidence=0.5, min_pose_presence_confidence=0.5, min_tracking_confidence=0.5):
self.model_path = model_path
self.video_path = video_path
self.load_dir = load_dir
self.save_dir = save_dir
self.num_poses = num_poses
self.min_pose_detection_confidence = min_pose_detection_confidence
self.min_pose_presence_confidence = min_pose_presence_confidence
self.min_tracking_confidence = min_tracking_confidence
self.to_window = None
self.last_timestamp_ms = 0
self.base_options = python.BaseOptions(model_asset_path=self.model_path)
self.options = vision.PoseLandmarkerOptions(
base_options=self.base_options,
running_mode=vision.RunningMode.LIVE_STREAM,
num_poses=self.num_poses,
min_pose_detection_confidence=self.min_pose_detection_confidence,
min_pose_presence_confidence=self.min_pose_presence_confidence,
min_tracking_confidence=self.min_tracking_confidence,
output_segmentation_masks=False,
result_callback=self.print_result
)
self.landmark_arr = []
def video_load(self):
# Video 읽어오는 함수
if len(self.video_path) == 1: # video 영상이 한개 선택
self.video_source = os.path.join(self.load_dir, self.video_path[0])
print(self.video_source)
self.cap = cv2.VideoCapture(self.video_source)
self.width = int(self.cap.get(cv2.CAP_PROP_FRAME_WIDTH))
self.height = int(self.cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
if not self.cap.isOpened():
showinfo(message="비디오를 읽어올 수 없습니다.")
else:
self.cap = self.cap
self.cap.release()
else:
print("V3.3.1 버전상 다중 영상 동시처리는 아직 불가합니다.")
def draw_landmarks_on_image(self, rgb_image, detection_result):
pose_landmarks_list = detection_result.pose_landmarks
annotated_image = np.copy(rgb_image)
person_li = []
for idx in range(len(pose_landmarks_list)):
pose_landmarks = pose_landmarks_list[idx]
pose_landmarks_proto = landmark_pb2.NormalizedLandmarkList()
pose_landmarks_proto.landmark.extend([
landmark_pb2.NormalizedLandmark(
x=landmark.x,
y=landmark.y,
z=landmark.z) for landmark in pose_landmarks
])
peak_array = []
for landmark in pose_landmarks:
peak_array.append([landmark.x, landmark.y, landmark.z])
person_li.append(np.array(peak_array))
mp.solutions.drawing_utils.draw_landmarks(
annotated_image,
pose_landmarks_proto,
mp.solutions.pose.POSE_CONNECTIONS,
mp.solutions.drawing_styles.get_default_pose_landmarks_style())
self.landmark_arr.append(np.array(person_li))
return annotated_image
def print_result(self, detection_result: vision.PoseLandmarkerResult, output_image: mp.Image, timestamp_ms: int):
if timestamp_ms < self.last_timestamp_ms:
return
self.last_timestamp_ms = timestamp_ms
self.to_window = cv2.cvtColor(
self.draw_landmarks_on_image(output_image.numpy_view(), detection_result), cv2.COLOR_RGB2BGR)
def detect_pose_landmarks(self):
temp_dir = tempfile.mkdtemp()
os.makedirs(name = self.save_dir, exist_ok = True)
temp_video_path = os.path.abspath(os.path.join(self.save_dir, self.video_path[0]+'_m.mp4'))
print('#'*100)
print(temp_video_path)
print('#'*100)
self.fourcc = cv2.VideoWriter_fourcc(*'avc1')
out = cv2.VideoWriter(temp_video_path, self.fourcc, 30.0, (self.width, self.height))
with vision.PoseLandmarker.create_from_options(self.options) as landmarker:
cap = cv2.VideoCapture(self.video_source)
while cap.isOpened():
success, image = cap.read()
if not success:
print("Image capture failed.")
break
mp_image = mp.Image(
image_format=mp.ImageFormat.SRGB,
data=cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
timestamp_ms = int(time.time() * 1000)
landmarker.detect_async(mp_image, timestamp_ms)
if self.to_window is not None:
# out.write(self.to_window) #<<--- SAVE VIDEO TO temp_video_path
cv2.imshow("MediaPipe Pose Landmark", self.to_window) #<<--- SHOW VIDEO
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
out.release()
cv2.destroyAllWindows()
array = np.transpose(np.array(self.landmark_arr), (1,0,2,3))
return array, temp_video_path
def add_center(self, landmark):
"""add_center 함수 : 랜드마크 배열에 center 랜드마크 추가하는 함수
Args:
landmark : 랜드마크 배열 (Frame, Person, Landmark, 3)
Returns:
landmark : 랜드마크 배열 (Frame, Person, Landmark, 3)
"""
landmark = np.concatenate([landmark, np.mean(landmark[:, :, [11, 23], :], axis=2, keepdims=True)], axis=2) # add center left indices(xyz)
landmark = np.concatenate([landmark, np.mean(landmark[:, :, [12, 24], :], axis=2, keepdims=True)], axis=2) # add center right indices(xyz)
return landmark
def run(self):
"""run 함수 : 비디오를 읽고 랜드마크를 그리는 함수
Returns:
self.array : 랜드마크 배열 (Frame, Person, Landmark, 3)
self.temp_video_path : 랜드마크가 그려진 비디오 경로
"""
self.video_load()
self.array, self.temp_video_path = self.detect_pose_landmarks()
self.array = self.add_center(landmark = self.array) # (2, 1066, 35, 3) => (person, frame, landmark, xyz)
return self.array, self.temp_video_path
if __name__ == '__main__':
start_time = time.time() # 시작 시간 기록
# model_path src : https://developers.google.com/mediapipe/solutions/vision/pose_landmarker#models
detector = PoseMultiDetector(video_path=["{filename}.mp4"], load_dir="{load file dir path}", save_dir="{save dir path}", model_path="{model path}")
array, temp_video_path = detector.run()
end_time = time.time() # 종료 시간 기록
elapsed_time = end_time - start_time # 실행 시간 계산
print(f"실행 시간: {elapsed_time}초")
추론시간은 아래와 같으며 단일 사람에 대한 추정에 비해 평균적으로 0.3초가량만 늘어나는 것을 보니 yolo로 person detection 후 사용하는 것보다 훨씬 빠르고 멀티 스레드 방식을 직접 사용하지 않아도 되어(미디어파이프의 내부에서 멀티 스레드를 사용할 수도 있습니다.) 오히려 초보자분들에게 더 좋을 것 같습니다.
Inference Time *video time : 35.75 sec
| type | Single Person[s] | Multiple Person[s] |
| video play time | 16.596126317977905 | 16.426476001739502 |
| video save time | 17.615072965621954 | 17.7233123124511523 |
| play + save time | 17.789123712419123 | 17.893999099731445 |